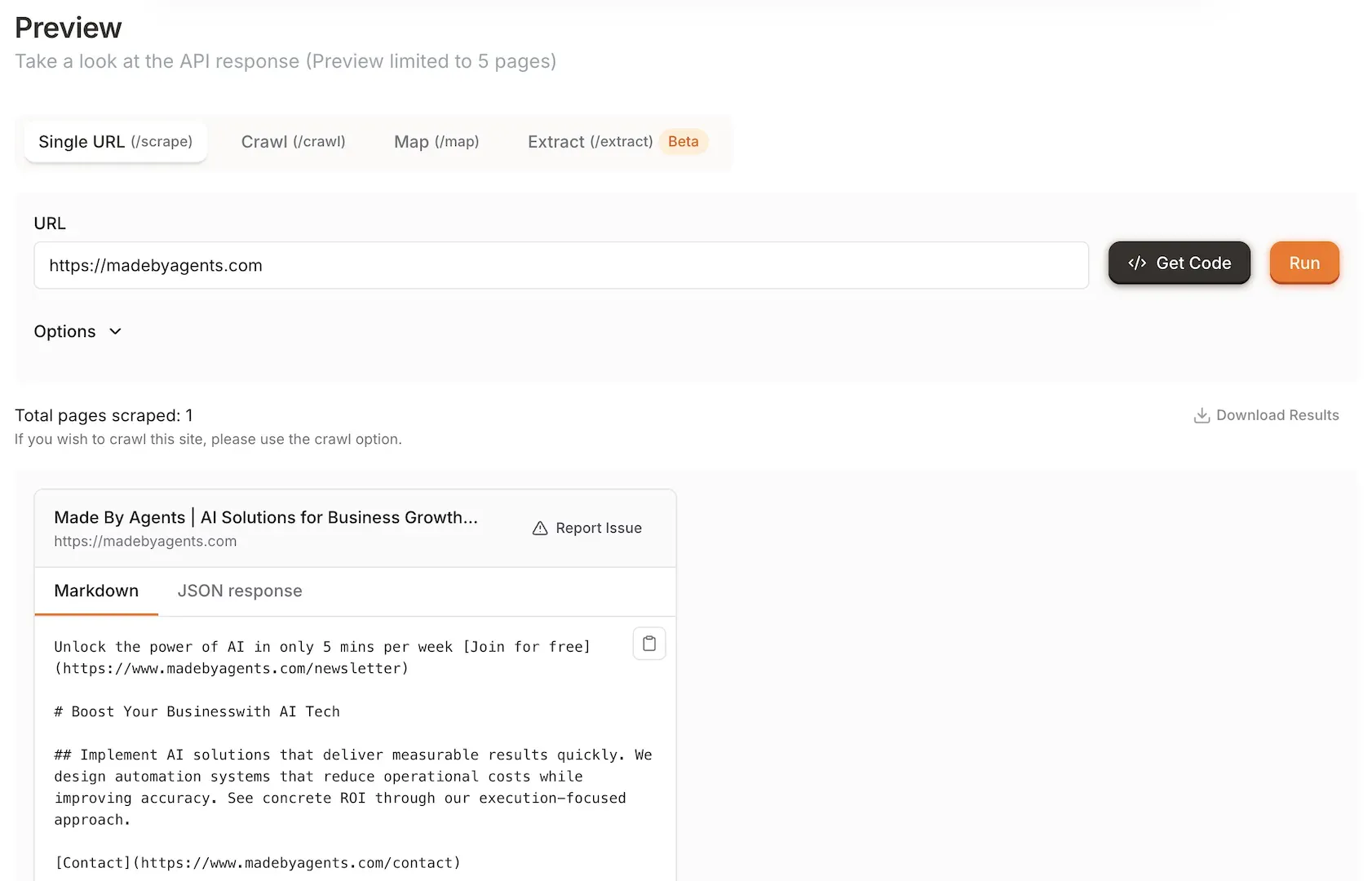
AI-powered web scraping tool that converts websites into clean markdown or structured data with intelligent rate limiting and proxy management.
REST API, Python, LlamaIndex, JavaScript/TypeScript, Zapier, LangChain, CrewAI
Cloud
Intermediate
Firecrawl is a next-generation web scraping and crawling tool that transforms complex data extraction tasks into automated workflows. It handles both simple page scraping and complete website crawling with equal efficiency. The system intelligently renders JavaScript content, adjusts request rates based on website responses, and manages proxies to avoid blocks. Firecrawl delivers clean, LLM-ready markdown or structured data extracted through AI, making it ideal for data collection at any scale. Available as both a hosted API service and an open-source solution for self-hosting.
Automatically adjusts scraping speed based on website conditions, slowing down during peak times and speeding up during quiet periods to avoid blocks while maintaining consistent data collection.
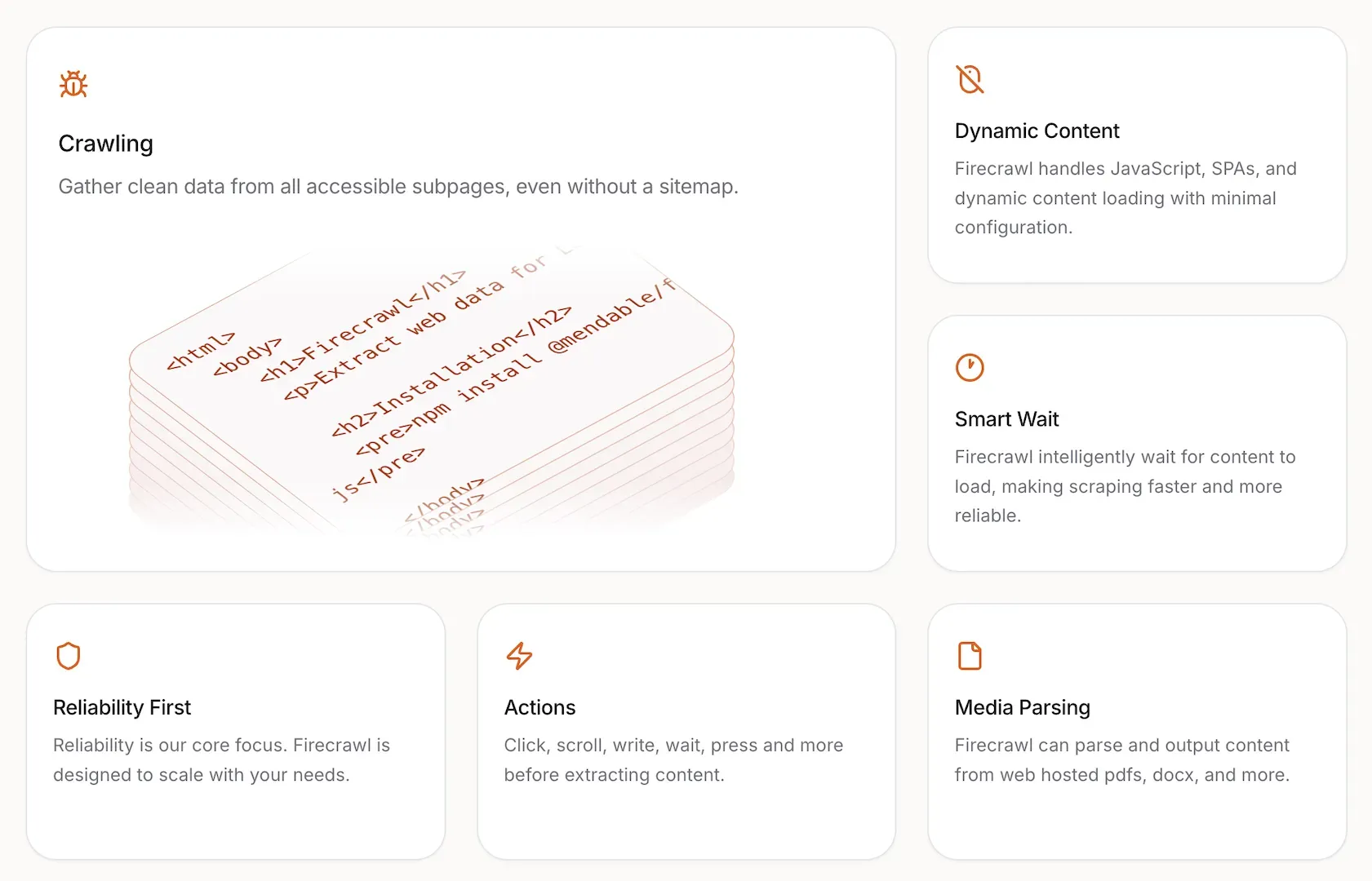
Built-in system automatically rotates proxies, handles failed requests, and maintains uptime without manual intervention, preventing IP blocks during high-volume scraping operations.
Uses AI to transform raw HTML into clean, structured data formats without requiring complex selectors, making data immediately usable for analysis or LLM training.
Maps and scrapes entire websites without requiring a sitemap, discovering and processing all accessible subpages in parallel for maximum efficiency.
Processes JavaScript-heavy websites by fully rendering page content in a real Chrome browser, ensuring complete data extraction from dynamic web applications.
Scales from hundreds to millions of pages through multi-threaded architecture that automatically balances load and manages resources for optimal performance.
Collect clean, well-structured training data from websites for building and fine-tuning large language models, RAG systems, and other AI applications that require web-based knowledge.
Extract contact information, company details, and professional profiles from business directories and professional networks to fuel sales pipelines with qualified prospects.
Gather comprehensive industry data from company websites, news sources, and public databases to identify trends, track competitors, and inform strategic decisions without manual research efforts.
Track product prices, inventory, specifications, and reviews across multiple retail sites automatically. Perfect for price monitoring, competitive analysis, and market intelligence in the retail sector.
Sign up on Firecrawl website to get an API key
Choose your preferred integration method (direct API or SDK)
Install SDK for your programming language (Python, Node.js, Go, or Rust)
Configure rate limits and proxy settings if needed
Start making API calls to extract website data
Alternatively, self-host the backend following the guide in GitHub repository
AI-powered web scraping tool using natural language queries instead of XPath/DOM selectors for reliable data extraction from any website.
Apify is a web scraping platform that extracts data from websites and automates web tasks using ready-made or custom scrapers.
Open-source LLM-friendly web crawler and scraper for extracting structured data from websites with AI-optimized outputs.
A Node.js and Python library for reliable web scraping and browser automation supporting HTTP requests, Puppeteer, and Playwright with built-in scaling.