How AI is revolutionizing web scraping. Discover cost-effective tools, build a robust scraping dashboard, and solve common data extraction challenges.
Listen to this AI-generated podcast summarizing the article content for easier digestion
Traditional web scraping is dead. Imagine spending weeks setting up a system to collect data from the web for your business. Then, the website structure changes, and suddenly your data collection stops working. This is a common challenge everyone faces who collects data from the web - unless you're using AI.
In this comprehensive guide, I'll show you how I solved this headache and built an AI-powered scraping dashboard that continues working even when websites completely redesign their pages. No code changes needed. That's the power of combining traditional scraping with AI.
By the end of this article, you'll understand:
To demonstrate these concepts, I'll compare six different approaches using two test cases:
A job board that can be easily scraped without being blocked
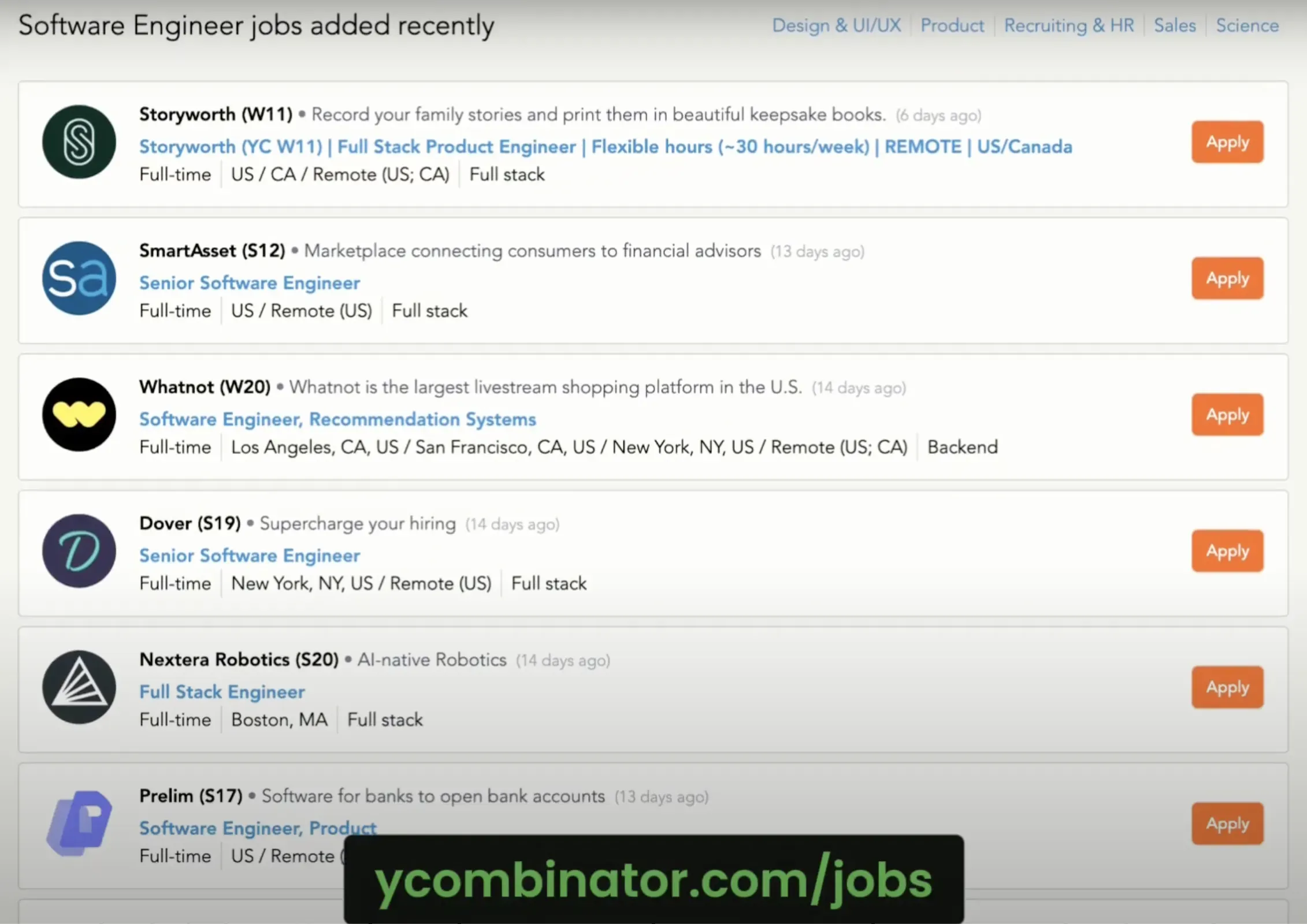
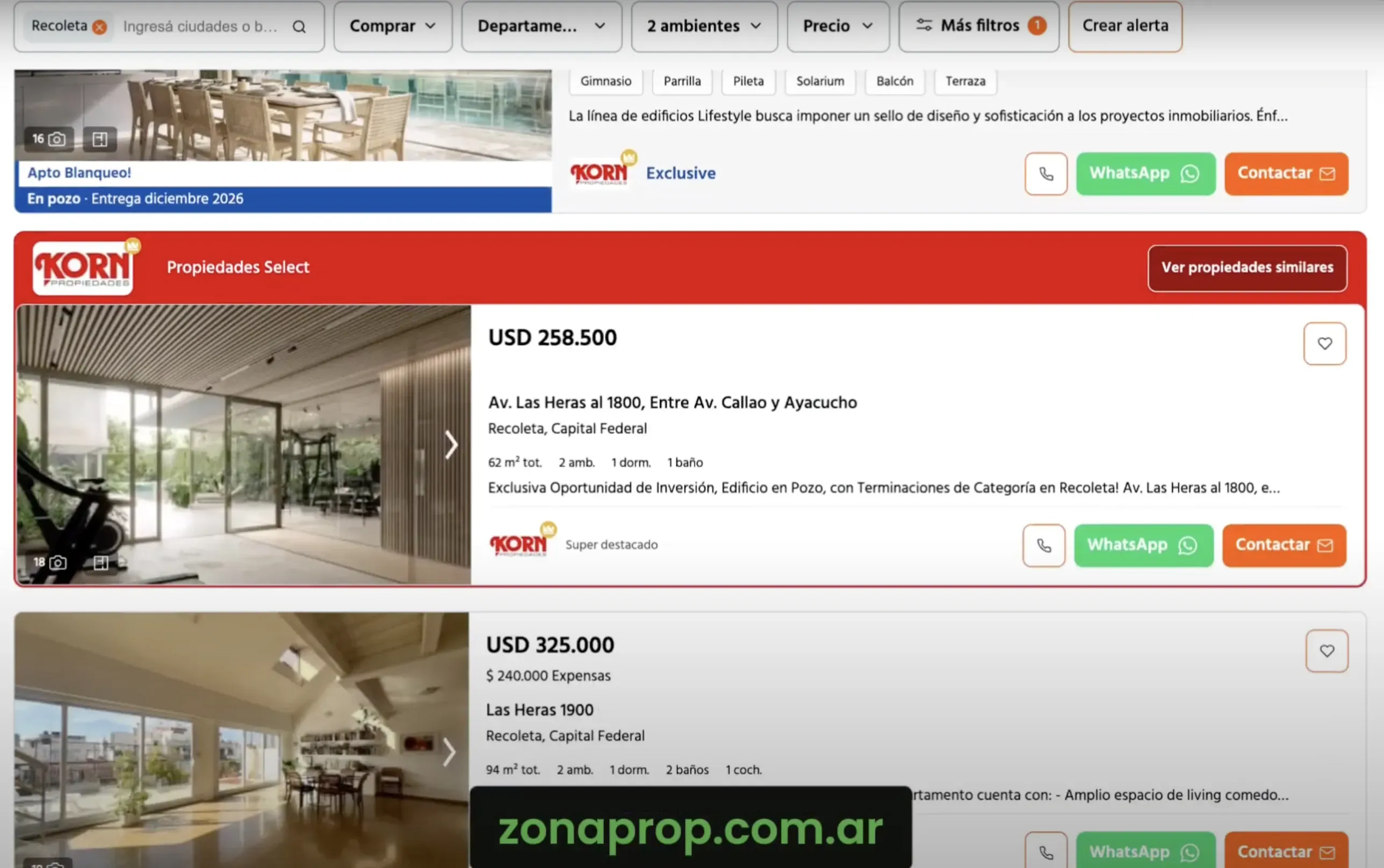
A real estate listing site from Argentina with anti-bot measures
Let's start with Beautiful Soup, probably the most popular scraping tool around. Beautiful Soup is typically used in combination with the requests package. Here's what you need to know about this traditional approach:
A key component often needed in traditional scraping is a proxy server. Here's why:
Let me show you how traditional scraping works. First, you inspect the HTML and find selectors for the data you want to scrape. Here's a basic Python script using requests and Beautiful Soup:
1import requests2from bs4 import BeautifulSoup34def scrape_jobs():5 # Define the URL to scrape6 url = "<https://example-job-board.com>"78 # Define headers to mimic human behavior9 headers = {10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"11 }1213 # Download HTML14 response = requests.get(url, headers=headers)15 soup = BeautifulSoup(response.content, 'html.parser')1617 # Find job listings18 jobs = soup.find_all('li', class_='job-listing')1920 results = []21 for job in jobs:22 job_data = {23 'company': job.find('div', class_='company-name').text.strip(),24 'title': job.find('h2', class_='job-title').text.strip(),25 'location': job.find('span', class_='location').text.strip(),26 'type': job.find('span', class_='job-type').text.strip()27 }28 results.append(job_data)2930 return results
When using this traditional approach with AI, you face a significant challenge: token costs. Let's break down the numbers:
This leads us to our first major insight: we need a more efficient way to prepare web data for AI processing. In the next section, we'll explore AI-powered scraping tools that solve these challenges while significantly reducing costs.
Let's dive into the tools that are revolutionizing web scraping with AI integration. I'll compare six different approaches, analyzing their features, costs, and real-world performance.
Jina.ai Reader represents a significant advancement in web scraping technology. Here's what makes it stand out:
Using Jina.ai is straightforward:
Overview of the Jina.ai playground
Let's compare the token usage:
The main challenge comes with protected websites:
Firecrawl takes a more comprehensive approach to AI-powered scraping.
Overview of the Firecrawl playground
Firecrawl's extract mode deserves special attention:
Example schema:
1{2 "jobs": {3 "company_name": "string",4 "job_title": "string",5 "location": "string"6 }7}
I tested Firecrawl on our Y Combinator job board example:
ScrapeGraph AI offers similar capabilities to Firecrawl but with some key differences.
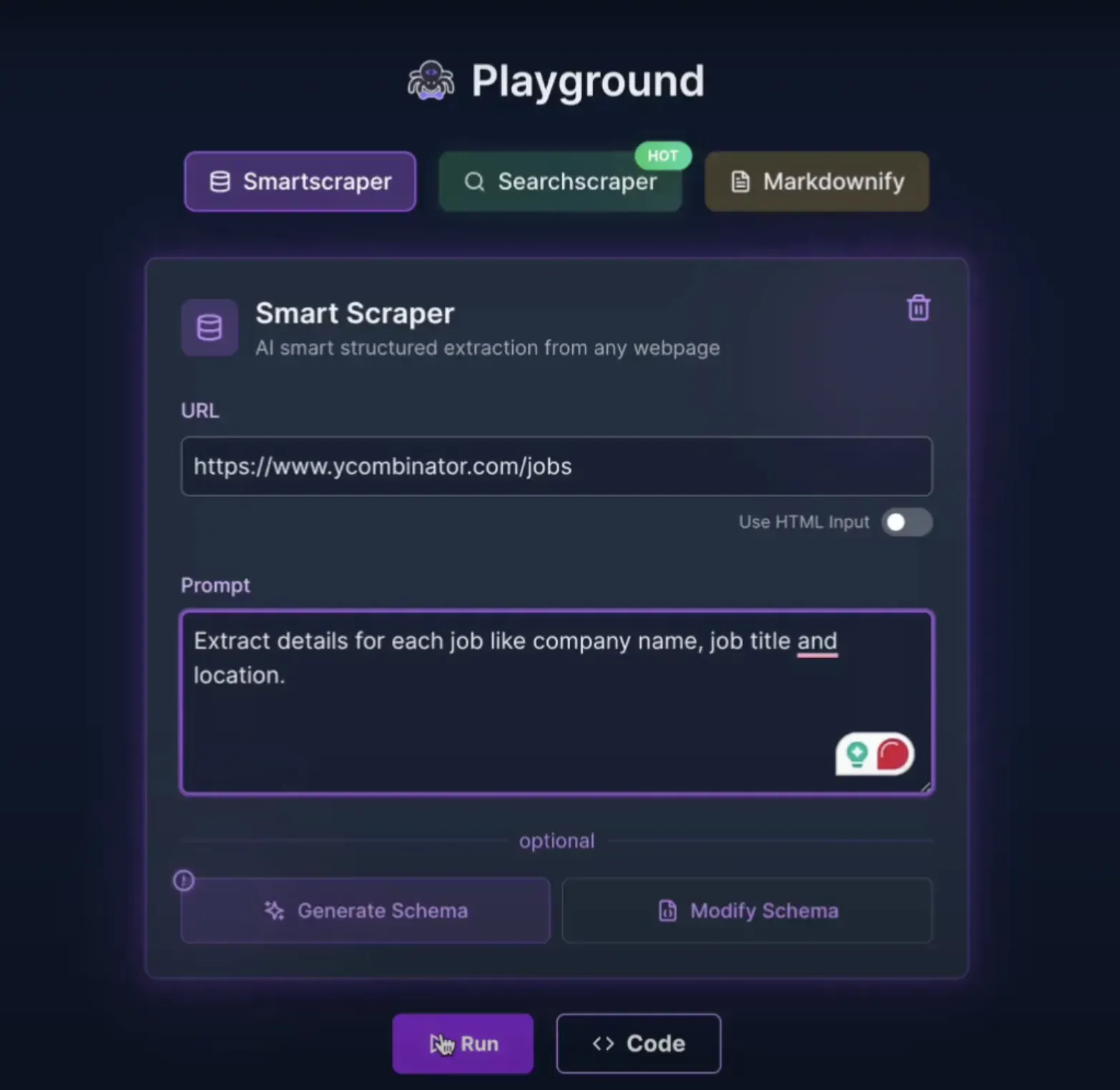
Overview of the ScrapeGraphAI playground
I tested ScrapeGraph AI on our job board example:
Prompt: "Extract details for each job: company name, job title, location"
Results:
AgentQL represents the next evolution in web scraping, bringing agentic features to the table.
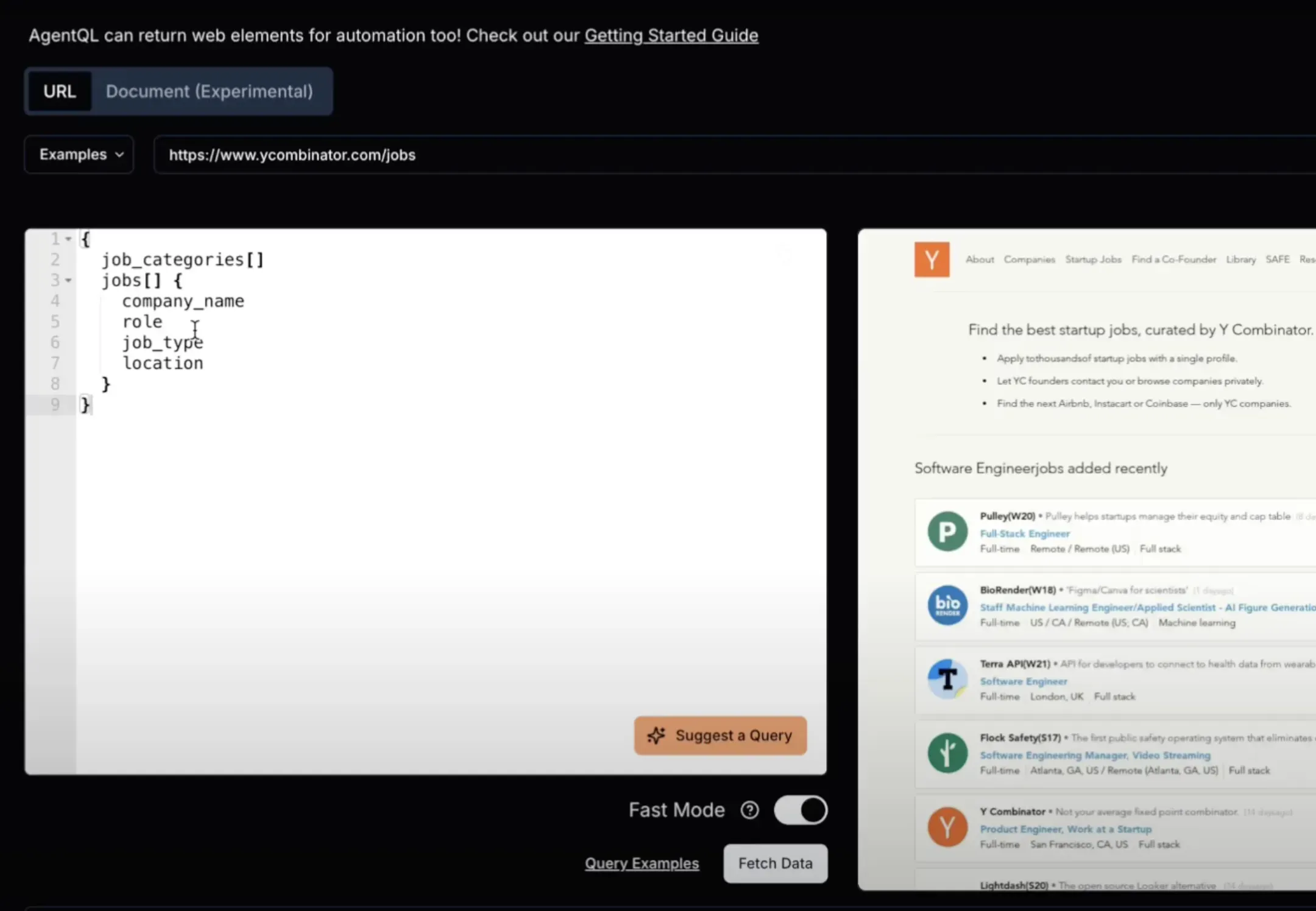
Overview of the AgentQL playground
Here's how to use AgentQL for form automation:
1import { AgentQL, PlaywrightBrowser } from 'agentql';23const config = {4 url: '<https://example.com/contact>',5 formQuery: `6 Find and fill these fields:7 - First Name8 - Last Name9 - Email Address10 - Subject (select field)11 - Comment12 Then click 'Continue' button and 'Confirm' button13 `,14 inputData: {15 firstName: 'John',16 lastName: 'Doe',17 email: '[email protected]',18 subject: 'General Inquiry',19 comment: 'Test message'20 }21};2223async function submitForm() {24 const browser = new PlaywrightBrowser();25 const agent = new AgentQL(browser);2627 await agent.navigate(config.url);28 await agent.fillForm(config.formQuery, config.inputData);29 await agent.waitForNavigation();3031 console.log('Form submitted successfully');32}
Crawlee represents the most sophisticated solution in our comparison, offering enterprise-grade features through the Apify platform.
A basic Crawlee scraper consists of two main configuration files:
main.ts
1import { Configuration } from 'crawlee';23export const config: Configuration = {4 startUrls: ['<https://example.com>'],5 proxyConfiguration: {6 useApifyProxy: true,7 countryCode: 'US'8 },9 maxRequestsPerCrawl: 1,10 // Additional configurations11};
routes.ts
1import { createCheerioRouter } from 'crawlee';2import { htmlToMarkdown } from 'some-markdown-converter';34export const router = createCheerioRouter();56router.addDefaultHandler(async ({ $, log }) => {7 // Clean HTML8 const cleanHtml = $('body')9 .clone()10 .find('script, style, meta, link')11 .remove()12 .end()13 .html();1415 // Convert to markdown16 const markdown = htmlToMarkdown(cleanHtml);1718 // Save results19 return {20 url: request.url,21 content: markdown,22 timestamp: new Date().toISOString()23 };24});25
1npm i -g apify-cli2apify login3apify push
Testing on the Argentine real estate site:
With our scraping infrastructure in place, selecting the right Language Model becomes crucial for efficient data processing.
I've developed a five-factor framework for LLM selection in AI web scraping:
Performance vs. Cost Balance
Feature Requirements
The third crucial factor in our framework is understanding and managing token limits:
Consider specialized capabilities needed for your scraping:
Let's break down the costs with a realistic example:
Solution: Model Testing Strategy
Solution: Parameter Control
Solution: Chunking Strategy
1def chunk_content(markdown_content, max_chunk_size=1000):2 """3 Break down large content into processable chunks4 while maintaining context5 """6 chunks = []7 current_chunk = []8 current_size = 0910 for line in markdown_content.split('\\\\n'):11 line_size = len(line.split())1213 if current_size + line_size > max_chunk_size:14 chunks.append('\\\\n'.join(current_chunk))15 current_chunk = [line]16 current_size = line_size17 else:18 current_chunk.append(line)19 current_size += line_size2021 if current_chunk:22 chunks.append('\\\\n'.join(current_chunk))2324 return chunks
Let's dive into the practical implementation of our scraping system.
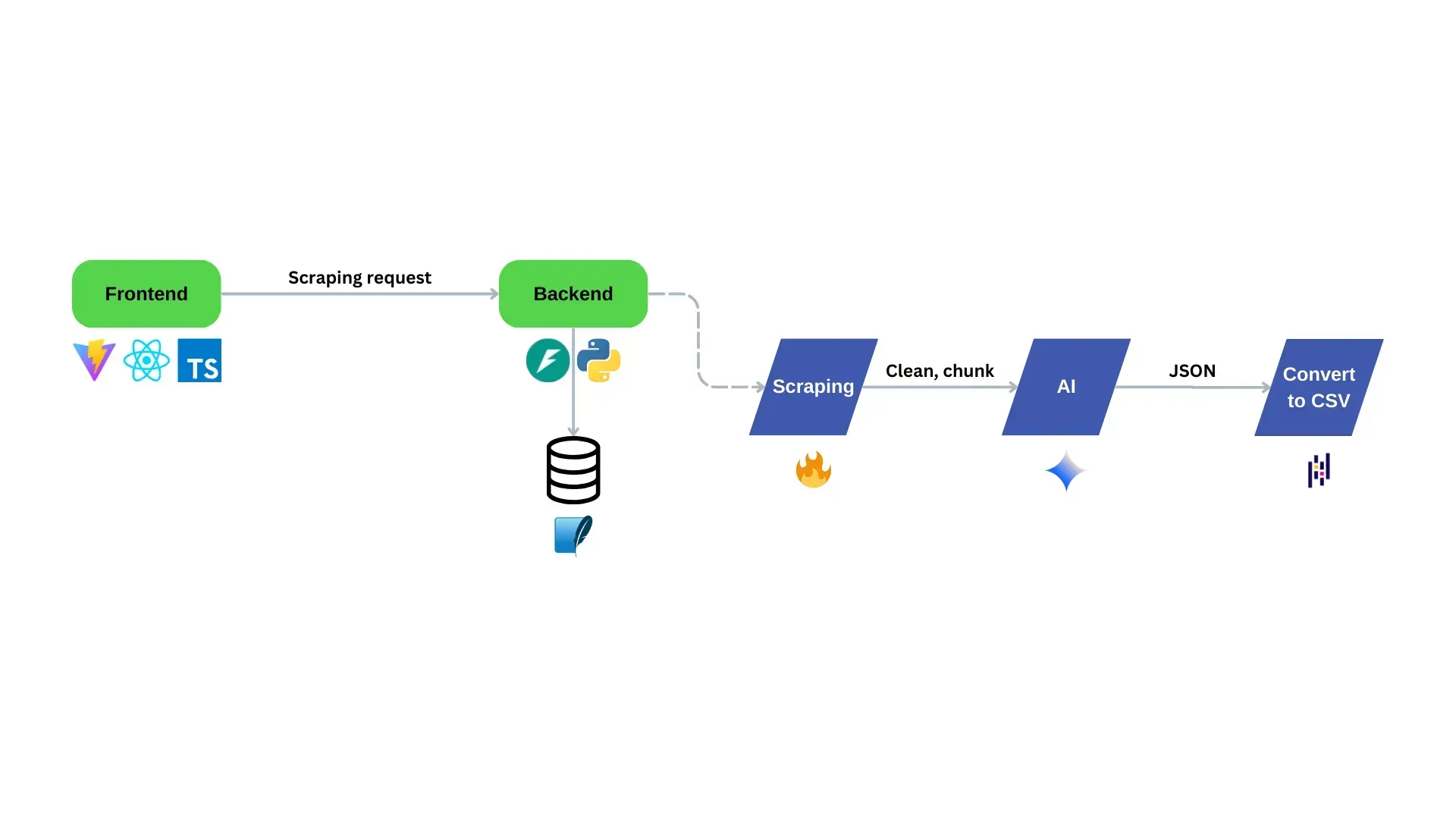
Flow chart of an architecture overview of the AI scraping dashboard
I walk you through the core processing function in my video above. Take a look if you’re interested.
If you’re interested in the dashboard features, I also invite you to watch the last quarter of my video where I walk you through the app.
Based on user feedback and testing, here are the planned enhancements:
The idea is to transform basic scraping into rich data insights. The scraped data can be used as input for another LLM call. This time the AI agents performs a web search for additional context. Think about a location-based data enhancement:
Improve multi-user support to make sure that the server can always handle the load:
Expand data delivery capabilities. The user can download the scraped data in different formats:
Streamline the commercial aspects by integrating Stripe:
Enhance data management by integrating cloud storage:
Add flexibility to data extraction. Users can define which data they want to receive:
Implement data analysis features to represent data visually:
The future of web scraping is here, and it's powered by AI. By combining traditional scraping techniques with modern AI capabilities, we've built a system that's:
Stay updated with the latest in AI scraping. Subscribe to our free newsletter for:
I'm planning a deep-dive series on building specific scrapers for different use cases. Let me know in the comments which specific scrapers you'd like to see built in detail.
Author's Note: This article is based on current technologies and pricing as of early 2025. Check the official documentation of each tool for the most up-to-date information.
Keep reading
We write about coding agents, multi-agent systems, AI pair programming, and the engineering practices we use with clients. Hands-on lessons from real projects, not high-level theory.
Browse all articles





