A Node.js and Python library for reliable web scraping and browser automation supporting HTTP requests, Puppeteer, and Playwright with built-in scaling.
Apify, AWS Lambda, Google Cloud, REST API
On Premise, Cloud
Intermediate
Crawlee is an open-source web scraping and browser automation library built for Node.js and Python. It helps developers create reliable crawlers with minimal effort. The library handles the complex parts of web scraping like proxy rotation, request queuing, and data storage. Crawlee supports both simple HTTP requests and headless browsers, making it versatile for different scraping needs. It's built by people who scrape for a living and used daily to crawl millions of pages.
Rotates proxies intelligently with human-like fingerprints to reduce blocking. Automatically discards problematic proxies.
Includes tools for extracting social handles, phone numbers, infinite scrolling, and blocking unwanted assets.
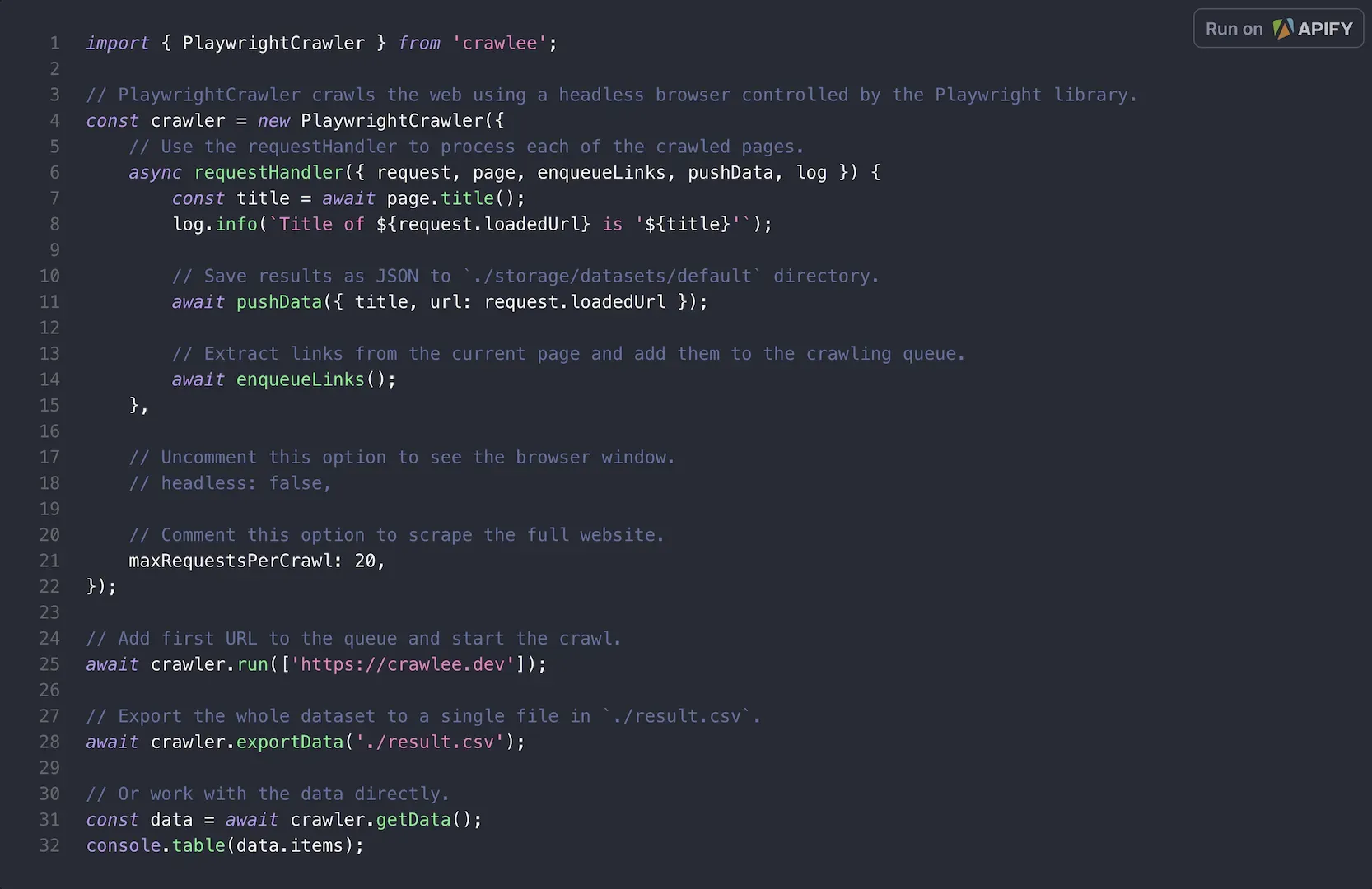
Choose between HTTP crawling with Cheerio/JSDOM parsers or browser automation with Puppeteer/Playwright for JavaScript-heavy sites.
Built-in request queue ensures URL uniqueness and preserves progress. Includes dataset storage for saving structured results.
Mimics browser headers and TLS fingerprints with automatic rotation based on real-world traffic patterns.
Manages concurrency based on available system resources to optimize performance without overloading your machine.
Collect structured data from websites for analysis, research, or integration with other systems.
Use browser automation capabilities to test web applications across different scenarios.
Track changes on websites and collect updates automatically for monitoring competitors or market changes.
Gather pricing, product information, and other competitive data from multiple sources automatically.
Extract contact information and business details from websites for sales and marketing purposes.
Install Node.js 16 or higher
Run "npx crawlee create my-crawler" or install manually with "npm install crawlee"
Choose your crawler type (Cheerio, Puppeteer, or Playwright)
Implement the request handler to process page content
Add starting URLs and run the crawler
AI-powered web scraping tool using natural language queries instead of XPath/DOM selectors for reliable data extraction from any website.
Apify is a web scraping platform that extracts data from websites and automates web tasks using ready-made or custom scrapers.
Open-source LLM-friendly web crawler and scraper for extracting structured data from websites with AI-optimized outputs.
Framework for orchestrating collaborative AI agents that work together to solve complex tasks through role-based specialization and teamwork.