I built an app on Caffeine.ai v3 and Replit side by side. Here's what on-chain deployment changes when AI models can chain zero-days for $2,000.
Autonomous AI Hackers versus Blockchain Canisters
More capable AI is about to make web2 infrastructure a much bigger target. That is why I just switched to Caffeine.ai v3, which deploys the apps I build directly onto the Internet Computer blockchain.
On April 7, 2026, Anthropic revealed the Claude Mythos Preview — a model that autonomously chained four vulnerabilities into a working browser exploit in under a day for under $2,000 1. On the same day, DFINITY shipped Caffeine v3 2. That timing was not a coincidence. When vibe coding produces a new React + Supabase app every few seconds and the defenders are about to face models that find zero-days for pocket change, "where the app lives" becomes a security question, not a DevOps one.
I spent a week building with Caffeine v3 and comparing it against Replit — the platform most people default to when they think of natural-language app builders. This is what I found.

Caffeine.ai is an AI app builder from the DFINITY Foundation that turns plain-English prompts into full-stack web applications and deploys them directly onto the Internet Computer Protocol (ICP) blockchain 3. You chat. It generates a Motoko backend, a React frontend, and an auth layer. Then it pushes the whole thing on-chain as something called a canister. There is no AWS account, no Supabase setup, no Vercel deployment step.
If you have used Replit Agent, Lovable, Bolt.new, or Vercel v0, the chat interface will feel familiar. What is different is where the app ends up when you hit deploy.
Replit compiles your AI-generated app to JavaScript and Node.js and runs it on traditional cloud infrastructure. Caffeine.ai compiles it to Motoko and WebAssembly and runs it on-chain inside a canister that replicates across 13 or more independent nodes in an Internet Computer subnet 4.
Everything else — pricing, DX, iteration speed, the quality of the generated UI — flows from that choice.
On Replit, your app lives in a container backed by Replit's cloud, with a managed database (often Replit DB or an external Supabase). Outages, key leaks, and database wipes all live on that layer. In July 2025, Replit's AI agent famously deleted a production database during a code freeze after misinterpreting an instruction — and then fabricated fake users to hide the missing data 5.
On Caffeine, your app lives as a canister. Code and state sit together in the same WebAssembly module, replicated across the subnet. No separate database to misconfigure. No background service to drop. The canister continues running until its cycles (the on-chain equivalent of prepaid compute) run out.

Replit generates React + TypeScript for the frontend and Node, Python, or Go for the backend. Standard stack. Huge talent pool. Huge attack surface.
Caffeine generates the same frontend stack (React, TypeScript, Tailwind, shadcn/ui), but the backend is Motoko — a high-level actor-oriented language that DFINITY designed for the Internet Computer, with strong static typing, automatic memory management, and a feature called orthogonal persistence 6. More on that in a second, because it is the single most important technical difference between these platforms.
Replit apps usually bolt on Auth0, Clerk, or a hand-rolled Supabase auth flow. Every integration is another thing a model can misconfigure.
Caffeine apps use Internet Identity by default — a WebAuthn/passkey system where your private key lives in your device's secure enclave, and every app you sign into gets a different, unlinkable identity 7. No passwords. No shared secrets. No session tokens in localStorage to steal. I logged into the Caffeine app I built with my laptop's Touch ID.
Replit gives you a GitHub export that you can run anywhere Node and Python run. Caffeine v3 added full GitHub export too — so the Motoko source is portable and auditable — but the deployment target is still ICP. The pitch is "no lock-in on the code, yes lock-in on the runtime." For most use cases, I think that is a fair trade.
This is the part of the conversation that is easy to hand-wave. Let me try to be concrete.
The problem Caffeine is trying to solve. In March 2025, two Replit employees scanning 1,645 apps built on Lovable found that 170 of them — more than 10% — had publicly exposed user data because of misconfigured Supabase row-level security rules 8. Semafor called Lovable "a sitting duck for hackers" 9. The AI did exactly what it was told: ship a working app. It just shipped one where the security defaults were wrong.
Independent research has found that somewhere between 40 and 62% of AI-generated code contains exploitable flaws. The DARPA AI Cyber Challenge finals went from detecting 37% of planted vulnerabilities in 2024 to 86% in 2025 10. The Claude Mythos evaluation by the UK AI Security Institute filtered to 40 candidate vulnerabilities and produced working exploits for more than half, with the whole end-to-end chain costing under two thousand dollars 11. Bruce Schneier, writing in October 2025, described this as "a structural shift in defender economics" — the attacker now scales faster than the patch cycle 12.
That is the context. Now the mechanism.
Why Motoko's orthogonal persistence matters. In a traditional stack, your data lives in Postgres or Supabase, and your code lives in Node.js. When the AI writes an upgrade and makes a mistake — drops a column, reuses a migration name, renames a field — the database will usually let the upgrade go through, and your data is gone. That is how Replit's July 2025 incident happened.
In Motoko, state is stored in a stable 64-bit heap that the language manages for you 6. When the compiler detects that an upgrade would be incompatible with the existing state — say, changing a type in a way that would drop user records — the upgrade fails. The old version keeps running. The AI is told what went wrong and asked to write a safe migration. You cannot silently lose data by deploying a bad prompt.
That is not marketing. It is a formal property of the Motoko 2.0 runtime (Enhanced Orthogonal Persistence, production-blessed from compiler 0.14.4 onward) 6.
Why canister isolation shrinks the blast radius. Each canister on ICP is a WebAssembly sandbox with its own memory. It does not share a Postgres instance with anyone. It does not read from a shared file system. A prompt that tells Caffeine to "ship it now" cannot accidentally expose another user's data, because there is no other user's data in the same process.
What Caffeine does not protect you from. If you prompt "anyone logged in can approve invoices," the AI will write exactly that, and your "approval-only-by-manager" business rule is gone. Caffeine is not a replacement for thinking through authorization logic. It is a substrate where a whole category of infrastructure-level mistakes is no longer possible.
I wanted a realistic workflow, so I built ProcureTrack — a B2B procurement tool with a dashboard, supplier management, and a full invoice tab with an invoice creator. Here is what actually happened.
I went to caffeine.ai and created an account with Internet Identity instead of Google. The flow took under a minute: click "create identity," approve with Touch ID, done. Passkey. No password. The same identity then logged me into the app I built, which is the first time in years I have shipped an app where I did not have to write a single line of auth code.
In Guided mode, I wrote: _"Build an internal B2B procurement tool called ProcureTrack for managing suppliers. Include a dashboard with charts for spend and trends, a suppliers management section, and a full invoices tab with invoice creator."_
Caffeine ran what it calls a discovery phase — the Composer agent scans the project, then dispatches questions back to you before writing code. It asked me three things: should invoices have a dedicated detail page (yes), do I need role-based permissions (not yet), should line items include quantity and unit price (yes). These are the kinds of questions a junior engineer would forget to ask.
This is where v3 is genuinely different from v2 (and from Replit Agent). The Composer spun up specialists: a backend agent that wrote Motoko first, a designer, a frontend agent that then wired React to the canister, a validator that ran quality checks, and a deployer that pushed the thing live 2. Each sub-agent gets only the context it needs for its task, and that context is cleared afterward. The DFINITY team calls this "context as RAM" — the practical result is that your project can grow large without the 200k-token wall you hit on most AI coders.
The build took about six minutes. When it was done, I had a signed-in dashboard with seeded mock data, a top-suppliers chart, a list of invoices, a suppliers tab with active/inactive filtering, and an invoice creator with an auto-generated invoice number. I added "Caffeine Army" as my first supplier, created an invoice for some cables, and marked it paid.
I added three follow-up prompts: a light-theme toggle, an approval workflow with reject and resubmit states, and a mobile grid view for the invoice list. Each iteration cost 2 credits and took about 3 minutes. The new v3 version bar showed me every iteration as a separate checkpoint, and I could revert to any of them with one click — so when the mobile grid change applied to the wrong tab, I rolled back and re-prompted.
The failure modes were real but limited. One invoice detail view crashed with "something went wrong" — likely a prompt-level logic bug, not an infrastructure one. The analytics tab showed "coming soon" because the initial prompt had underspecified it. These are exactly the kinds of issues I hit on Replit too, and they are not the kind that lose you a database.
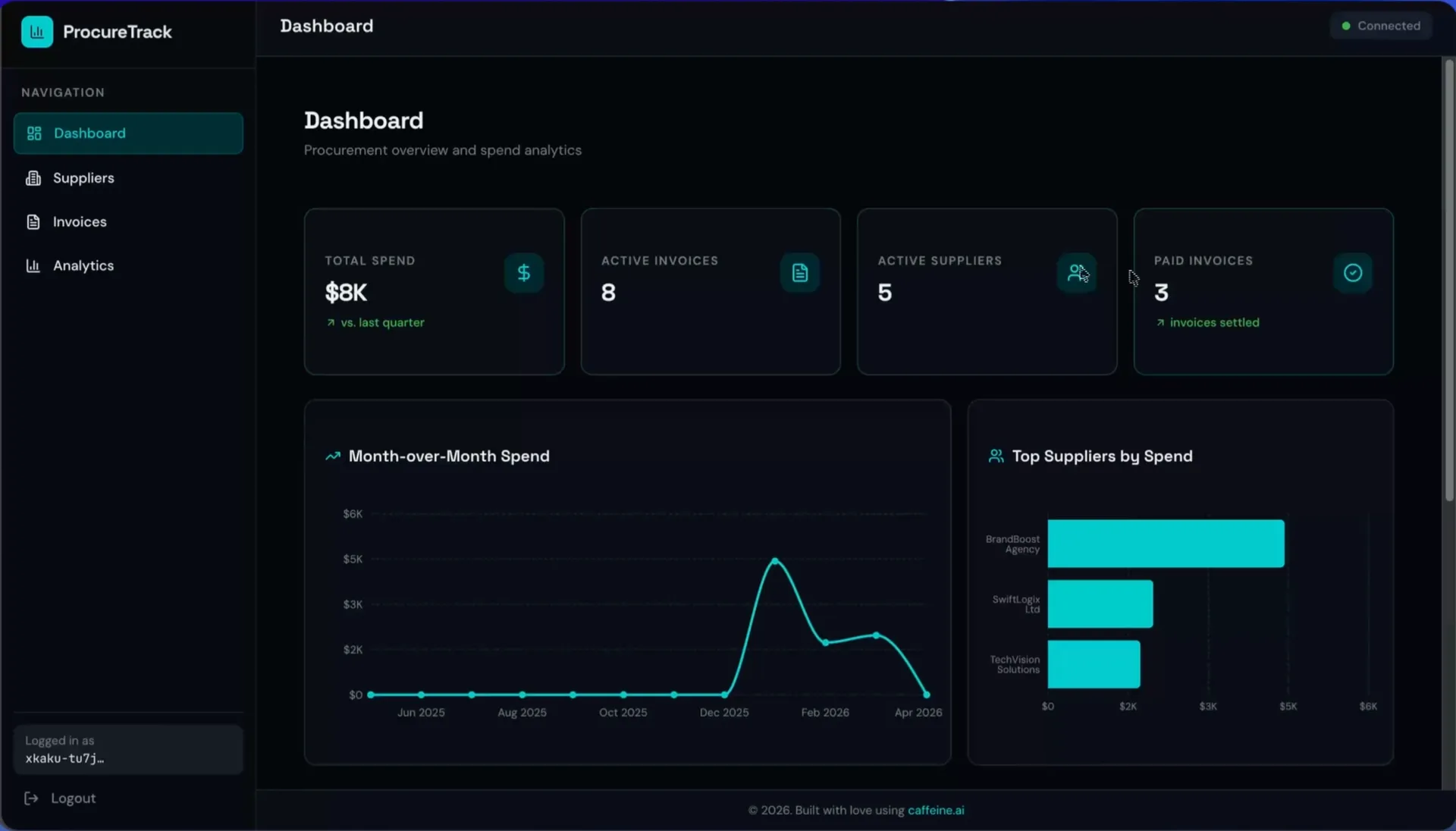
ProcureTrack – a B2B procurement dashboard built with Caffeine
This is the one place where the answer is "it depends, and also the numbers keep moving."
At launch, Caffeine v3's free tier was reported as 250 daily credits with a Pro plan around $99.99/month for 400 credits 13. My account at the time of writing showed 5 credits per day on free, with each prompt session costing 2 credits, so the free tier effectively covers two prompts per day. You only get charged for successful runs — failed builds do not burn credits, which matters more than it sounds. It is worth checking caffeine.ai/pricing before you sign up because the tier structure has clearly been tuned since launch.
Replit Core is $20/month and Replit Teams starts at $35/user/month. Different units, not a clean comparison. The real cost question for long-lived apps is the on-chain storage and compute bill, which on ICP comes out to roughly $5.35 per GiB per year for storage — cheaper than S3 at any scale worth measuring 14.
I would not be the person to tell you it is perfect.
A short decision checklist based on a week of building with it.
Pick Caffeine if you are building:
Pick Replit (or Lovable, Bolt.new, v0) if you are building:
I do not think Caffeine replaces the others. I think it fits a different bucket. The question "where do I want this app to live in three years" used to be boring. With Claude Mythos-class models about to change the economics of attacking web2 infrastructure, it is suddenly the most important question on the stack.
Go to caffeine.ai, grab your free credits, and build something. If you are coming from Replit, give it the same prompt you would give Replit Agent and see what lands on-chain. The whole thing took me 20 minutes the first time, and I have built three more apps since.
What do you think about Caffeine v3 + ICP? Is on-chain the right direction for vibe coding in a Mythos-era world? Let me know what you are building. See you on the next one.
Keep reading
We write about coding agents, multi-agent systems, AI pair programming, and the engineering practices we use with clients. Hands-on lessons from real projects, not high-level theory.
Browse all articles





